




根据欧盟人工智能法(EUAIA)的规定[1],生物识别技术、关键基础设施、教育和职业培训、执法、司法管理等八类AI应用场景,因涉及个人身份信息的保护、国家安全、公民公平权利等,而被归入了高风险的范畴[2]。其中场景之一是公民获取和使用基本私人服务和基本公共服务及福利的AI应用,涉及使用算法AI对申请人信用的评估。欧盟人工智能法在其立法背景中解释,用于决定自然人获取金融资源或者其他诸如住房、电力和电信服务等情况的,用于评估其信用分数或者个人可信度的AI系统将被视为高风险系统[3]。
高风险AI系统需要遵守该法律对其使用的数据和算法的治理规范要求。本文以消费者信用评级的一个概念模型为例,讨论AI算法系统开发和应用可能遇到的治理挑战,分析AI算法合规的适用要求,以期为AI和算法治理规则落地的方法和路径提供思路。
一、场景介绍:金融消费者信用评级概念模型
在个人信用卡业务中,传统商业银行评估个人信用情况时,一般依赖于客户个人的年龄、职业、收入情况、存款金额和现金流情况对申请人信用风险进行评估,以确定最终可以授信的额度(参见图一)。如果有银行自身或者外部机构的信用数据,评估将可能使用客户个人的历史信用记录数据。金融机构一般通过开发和使用算法,计算客户的信用评分,进而决定是否给予发放信用卡,以及具体的信用额度。算法通常需要通过较大规模的样本数据采集,对信用违约和信用评估的各类数据进行相关性和因果关系的分析验证,进而获得实证数据支持的信用评估算法模型。经过验证后的算法模型在一定时间内是相对稳定的,可以应用于实践中对信用卡申请人的信用评估。
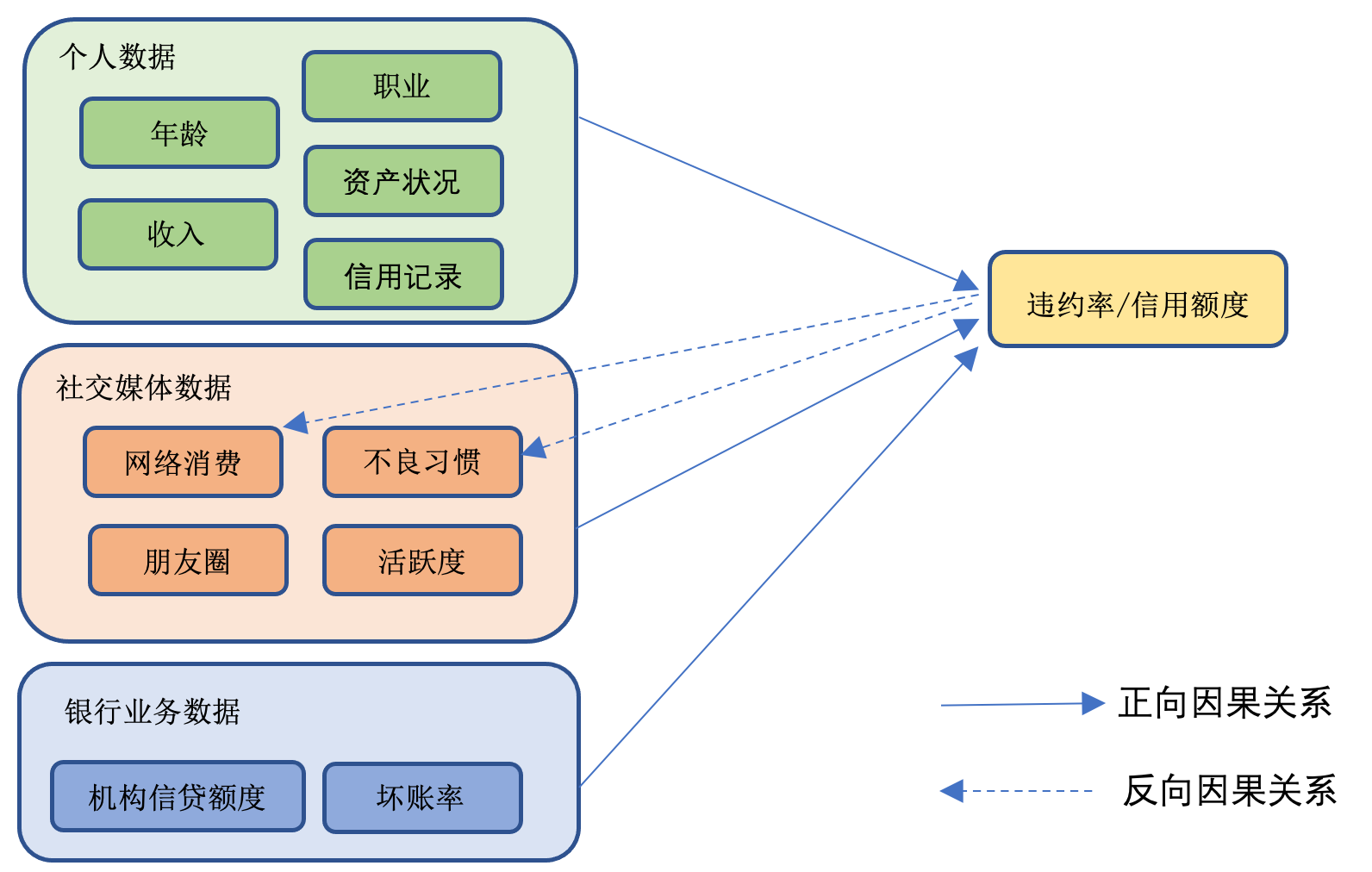
图一 个人信用评估的概念模型和因果关系分析
在个人信用评估算法模型的搭建过程中,个人存款、其他资产的规模、收入情况、历史信用记录、甚至该申请人使用其他信用卡消费的频率、金额或还款情况都可以成为评估个人信用情况的因子,占有不同的权重。在更为复杂的评估模型中,区分不同因素,评估因子的构成和权重分配可能会有不同的变化。
在能够获得各类数字化平台个人行为数据的情况下,评估算法甚至可以将个人的出行习惯、网络购物记录、社交媒体活跃度、朋友圈大小等因子也纳入个人信用评估的范畴。
二、信用评级模型的因果关系问题和算法构建
信用评估模型的核心是对各个因子的选择和权重衡量。例如,个人收入这一因子,预测着个人消费能力的水平,进而反映个人信用卡的还款能力。历史不良记录预示着个人未来出现信用违约的可能性。此外,社交媒体数据被分析加工,生成的一些标签化或者数据化的“不良”习惯可能预示着个人对其信用状况的“不关注”、“不看重”,因此将会有较高的“信用违约概率”。这些因果关系的确定建立在常识和实证研究的基础之上。在数据分析中,首先表现为各种指标因子与最终结果个人信用违约概率的相关性。
然而,仅凭数据相关性并不能直接证明因果关系的存在。两个指标因子之间存在相关性,并不能说明哪一个因子发生在前。两个因子的相关性也无法排除该相关性是由一个第三方因子发生作用的共同结果。这在各类社会科学和统计分析方法的研究中,已为众多研究人员关注,不同的研究方法和设计也被广泛采用于寻找和验证因果关系[4]。
在个人信用评估场景中,“不良”的标签是否存在其他的解释,而与信用状况无关?为了对算法所依赖的基础因果逻辑关系进行验证评估,在研究方法设计上,可以考察不同因子在时间上的先后逻辑顺序。例如,“历史消费记录”这个因子,信用评估的一个简单逻辑就是,在排除其他因素影响的情况下,个人消费越多,越能体现个人的经济实力,因此还款能力强,信用违约概率小。
但是,另一个完全相反的因果关系也可以解释同样的相关性现象。个人消费者获得的信用金额越大,越容易有消费的冲动,导致消费记录增多,消费金额变大。甚至是常见的“以卡养卡”的现象,也可以解释信用卡越多,信用卡消费记录越多的情况。
对因果逻辑关系的忽视可能引发违反社会公德和伦理、伤害公平公正原则的问题,甚至涉及损害未成年人、老年人、残障人士等特殊群体用户权益的潜在风险。在现有商业平台的大数据挖掘应用中,一个越来越显著的倾向是只关注数据相关性,不再考虑“前因”和“后果”[5]。例如,算法推荐服务中,只要客户曾经网购过某类商品,算法就会自动推荐同类商品。其基本逻辑是算法通过客户的购物记录预测该客户对其曾经购物的商品类别感兴趣。更进一步,只要客户浏览过某类商品,网络算法就不断推荐同类商品。这已经引起消费者对自身隐私保护的关注[6]。
在商品广告方面,这种逻辑造成的负面影响似乎不大。但是,在特定的应用场景下,不对因果先后的顺序进行关注,算法的有效性可能受到威胁,科学研究及其结果应用可能产生超出预期的偏差[7]。粗疏武断的因果关系判断会直接影响算法运用结论的有效性。基于此种原因,欧盟人工智能法和目前各国对人工智能立法的讨论都将算法模型设计目的与其应用的适当性作为基本要求,并以确保算法可解释性为重要的立法目的。
三、算法治理的规范要求和合规启示
算法设计和应用的绝大多数场景都可以归结为对因果关系的分析和验证。在不同数据之间寻找相关性,进而形成预测和应用的数学模型,是数据分析的一般方法。按照欧盟人工智能法的要求,针对不同类型的数据特点、样本规律、数学模型的限制、系统应用的目的、适用人群等多种因素,模型和系统的设计和应用研究将采取不同的数学量化方法,或设定一定的规则规范AI自我训练、自我学习的过程。整个方案、系统测试和应用测试的过程在研究方法上需要有一系列的考量,并对不同的方法做出选择[8]。
例如,数据之间的相关性并不直接预示着现实世界中的因果关系。一些现象和数据指标的同时出现,可能都是另一个因素发生作用的同时结果;也可能是在特定人员或者实验样本中的偶发现象。即使是有因果关系存在的可能,也需要对二者之间的先后顺序进行区分,确定谁是“因”、谁又是“果”。
对于依赖单纯数据相关性进而推导出因果关系的过程,算法的开发者应特别考虑基础理论和实证研究方法的历史研究成果和比较分析,把握合理的逻辑关系。对因果关系因子权重的精致梳理和评估是算法有效性的重要前提。
同时,也可以尝试使用时间序列研究、控制组比对等方式验证因果关系,排除其他合理的解释,进而建立科学、合理的模型[9]。
对于可能出现不同理论解释的因子,要关注提炼典型特征,在模型搭建中采取措施,对可能出现的特例进行特别处理。例如,对于“以卡养卡”等异常情况,商业银行通常会采取监控、调查、冻结等方式防范欺诈风险。而对于数据应用和算法模型的构建而言,落入异常活动监控或其他控制措施中的数据,则需要采取排除、另类处理的方法,去除噪音,防止数据影响信用评估算法模型的有效性。
注释:
[1] EUAIA第53页,第6条;第127-129页,附件III,法律文本可在本链接下载,ELI: http://data.europa.eu/eli/reg/2024/1689/oj
[2] 另见本系列文章之一: 环球科技法前沿系列 | 欧盟《人工智能法》合规路径思考——数据和数据治理规则,https://mp.weixin.qq.com/s/3aw0faBRP9E5IWSXiSlaFw
[3] EUAIA第16页。
[4] William R. Shadish, Thomas D. Cook, and, Donald T. Campbell (2002), Experimental and Quasi-Experimental Designs for Generalized Causal Inference, Houghton Mifflin Company: Boston, NY. Guido W. Imbens and Donald B. Rubin (2015) Causal Inference for Statistics, Social and Biomedical Sciences. Cambridge University Press. Paul W. Holland (1986) Statistics and Causal Inference, Journal of the American Statistical Association, 81:396, 945-960, Donald B. Rubin (2005) Causal Inference Using Potential Outcomes: Design, Modeling, Decisions. Journal of the American Statistical Association, 100(469), 322–331. http://www.jstor.org/stable/27590541
[5] Margherita Vestoso (2018) The GDPR beyond privacy: Data-driven challenges for social scientists, legislators and policy-makers. Future Internet 2018, 10, 62.
[6] 中国信息通信研究院、新华网大数据中心(2022)算法治理蓝皮书。在《互联网信息服务算法推荐管理规定》中,第十七条要求算法推荐服务提供者应当向用户提供不针对某个人特征的选项,或者向用户提供便捷的关闭算法推荐服务的选项,并向用户提供选择或者删除用于算法推荐服务的针对某个人特征的用户标签的功能。
[7] O’Neil, C (2017) Weapons of Math Destruction: How Big Data Increases inequality and threatens democracy. New York, NY: Broadway Book. David Lazer, Ryan Kennedy, Gary King and Alessandro Vespignani (2014) The Parable of Google Flu: Traps in Big Data Analysis. Science, Vol343, Pp1203-1205. 14 March 2014.
[8] EUAIA,第10条,第2段。
[9] 徐文鸣(2022)法学实证研究之反思:以因果性分析范式为视角,《比较法研究》,2022年第2期,第177-187页。Shadish, William R., Cook, Thomas D., and Campbell, Donald T., Experimental and Quasi-Experimental Designs for Generalized Causal Inference, Houghton Mifflin Company: Boston, NY. (2002), p.6-26.

